事件快讯
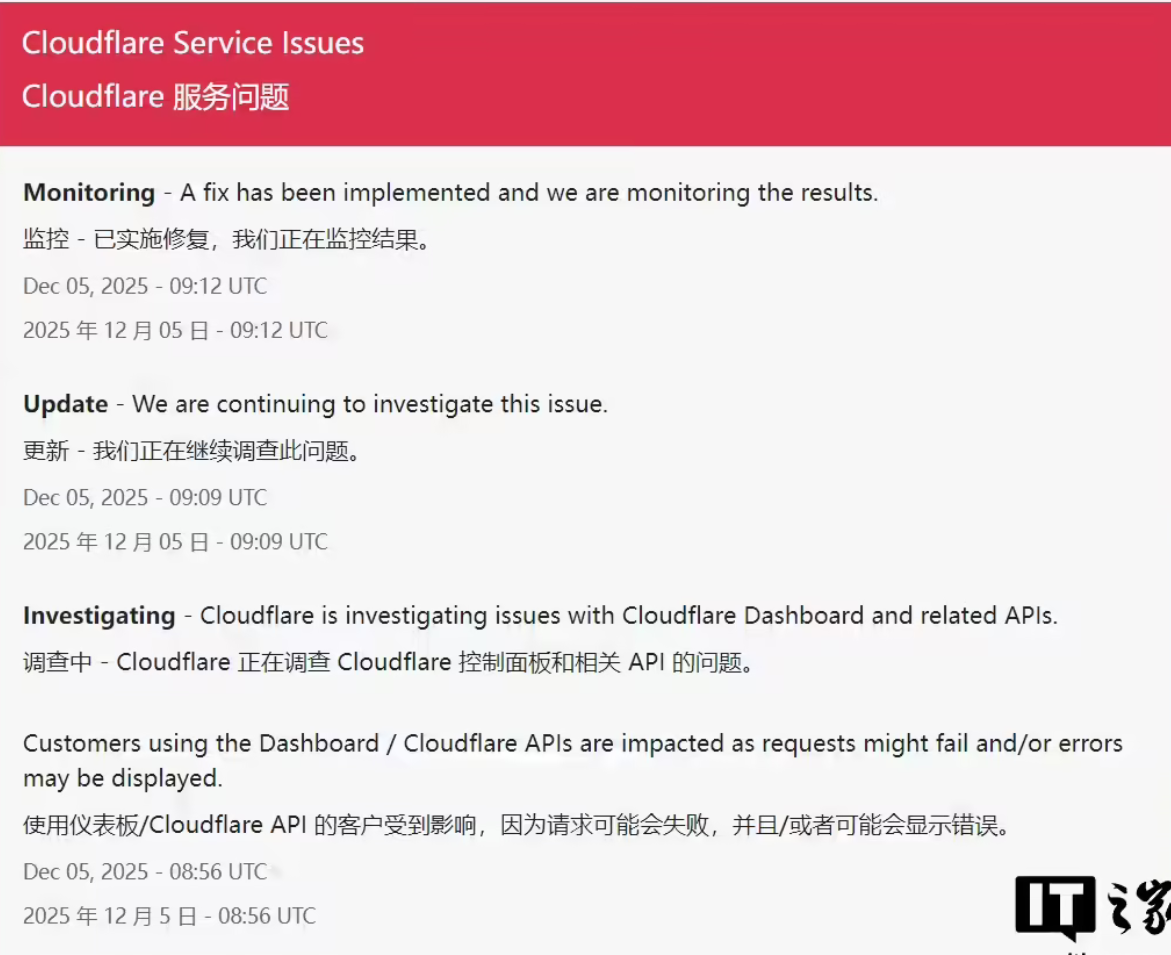
17:19 关键更新: Cloudflare官方状态页显示,影响其控制面板及相关API的服务问题已实施修复。工程师正在持续监控并调查事件的根本原因。
事件回顾:关键服务再度中断
北京时间12月5日,全球领先的内容分发网络(CDN)与网络安全服务商Cloudflare再次出现服务异常。据其官方状态页面披露,此次故障主要影响Cloudflare控制面板(仪表盘)及相关API,导致依赖这些接口的客户请求失败或收到错误信息。
此次宕机距离上一次大规模全球故障(11月18日)仅过去约半个月。彼时,包括社交平台X、OpenAI的ChatGPT在内的众多一线互联网服务出现访问问题,凸显了Cloudflare作为互联网底层“关键齿轮”的极端重要性。
影响范围:连锁反应显现
尽管Cloudflare强调其核心的CDN与安全防护服务(如DDoS缓解)在此次事件中保持运行,但控制面板与API的故障依然产生了连锁影响:
- 管理操作中断: 客户无法通过仪表板修改DNS记录、调整安全规则、查看分析数据或管理账户。
- 自动化流程失败: 依赖Cloudflare API进行自动化配置、部署或集成的服务和脚本出现错误。
- 用户反馈: 据社区及用户报告,Shopify、Zoom等平台的部分管理功能或集成服务受到波及,进一步印证了其生态影响的广度。
官方回应与关联动态
Cloudflare在事件调查中明确指出,此次故障与另一项计划内维护无关。该维护涉及对底特律和芝加哥数据中心的作业,官方已提前通告。
这一说明意在区分计划与非计划中断,但也引发了业内的进一步关注:在如此短的时间内,同一家顶级基础设施提供商接连发生运营事件,其背后的系统复杂性、变更管理及容灾韧性已成为必须审视的焦点。
主机帮视角:事件背后的安全与韧性启示
对于广大站长、运维及安全团队而言,此次事件远不止一则新闻,它提供了几个至关重要的实战警示:
- “单点故障”的现代形态: 现代互联网架构高度依赖像Cloudflare这样的全球化第三方服务。当其管理平面出现问题时,即便数据平面正常运行,用户的配置与管理能力也会被“冻结”,这构成了一种新型的业务风险。
- API依赖风险: 深度集成Cloudflare API以实现自动化运维,在提升效率的同时,也耦合了其API的可用性风险。需要为关键操作设计降级方案或手动后备路径。
- 监控与告警的独立性: 当Cloudflare仪表盘本身不可用时,依赖其内建分析进行业务监控的团队将陷入盲区。务必建立独立于服务商之外的第三方或自建监控体系,确保在服务商自身出问题时,你仍是第一个知情者。
- 灾难恢复计划(DRP)的必备项: 企业的灾难恢复计划中,必须纳入“关键第三方服务长时间不可用”的应对场景,并定期演练。
总结与行动建议
Cloudflare的快速修复能力值得肯定,但半月内的两次事件已为其所有用户敲响警钟:没有任何服务是100%可用的,即便它是互联网的基石。
我们建议您立即采取以下行动:
- 审查依赖: 明确您业务对Cloudflare各服务模块(DNS、CDN、WAF、API)的依赖程度。
- 配置备份: 为关键DNS记录、防火墙规则等重要配置保留本地备份,以便在紧急情况下能通过其他途径快速恢复。
- 设立冗余: 对于极端关键的业务,评估引入第二家CDN或DNS服务商作为地理或服务冗余的可行性。
- 沟通预案: 准备在第三方服务中断时,与您的用户进行透明沟通的预案。
互联网的韧性建立在分散与冗余之上。此次事件再次证明,将安全与可用性的责任部分寄托于外部时,保持自身的主动权和应变能力,才是构筑稳固防线的终极智慧。
(关注主机帮,获取第一时间的安全事件解读与实战防御指南。)