现在网上针对网站的恶意爬虫相当多,对网站造成影响非常大,轻则使网站访问卡慢,重则使服务器停止运行,而如果网站使用了CDN,还会对非常消耗CDN流量,造成财产损失,因此拦截恶意爬虫是非常重要的,使用京东云星盾可以有效拦截特定恶意爬虫抓取网站,以下是常见爬虫的拦截方法。
1.进入京东云星盾后台-安全规则
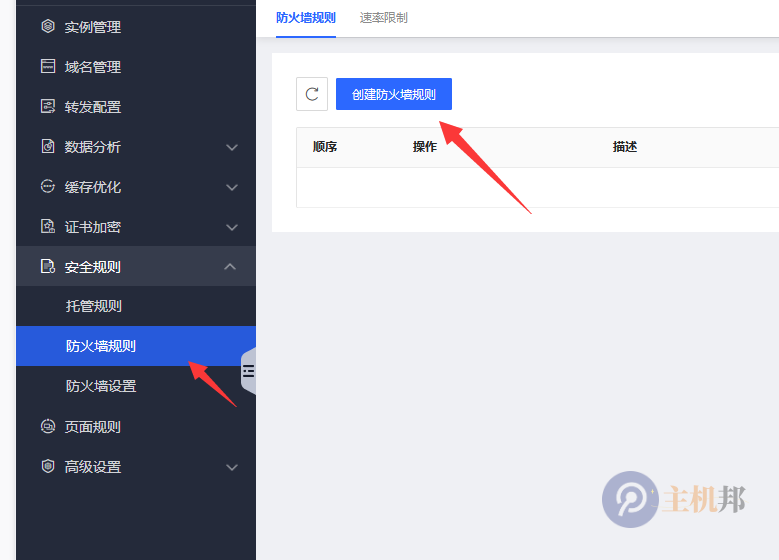
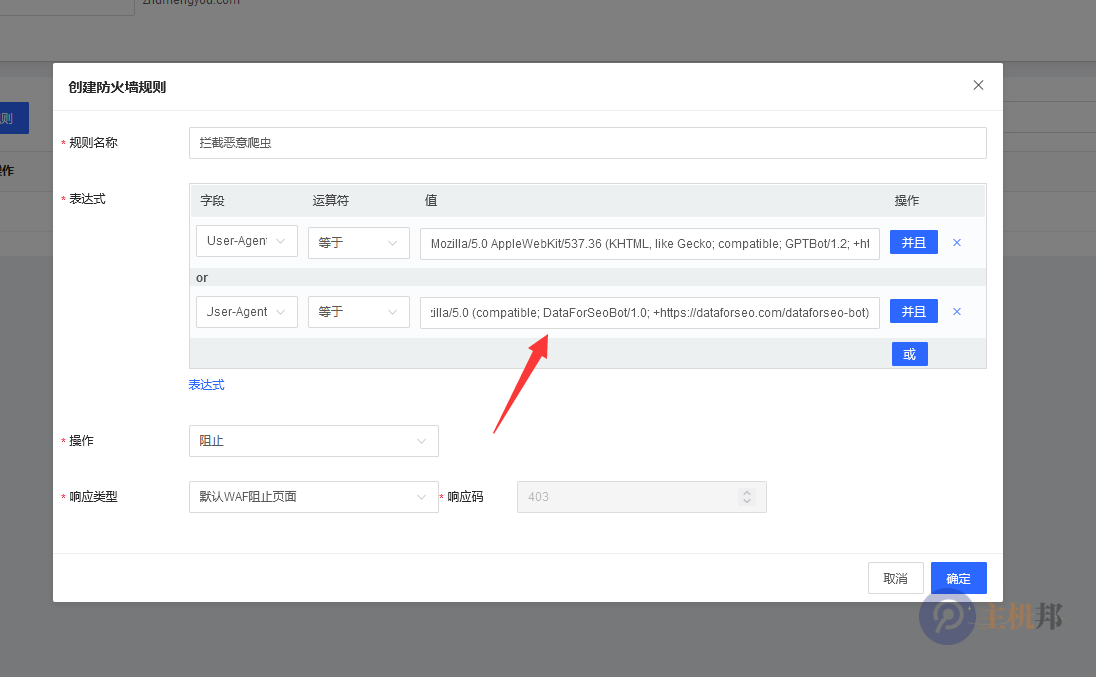
2.创建防火墙规则
规则名称:拦截恶意爬虫
字段:选User-Agent
运算符:等于
值:填写恶意爬虫的User-Agent,如chatgpt的User-Agent:
Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; GPTBot/1.2; +https://openai.com/gptbot)
操作:阻止
响应类型:默认
如下图:
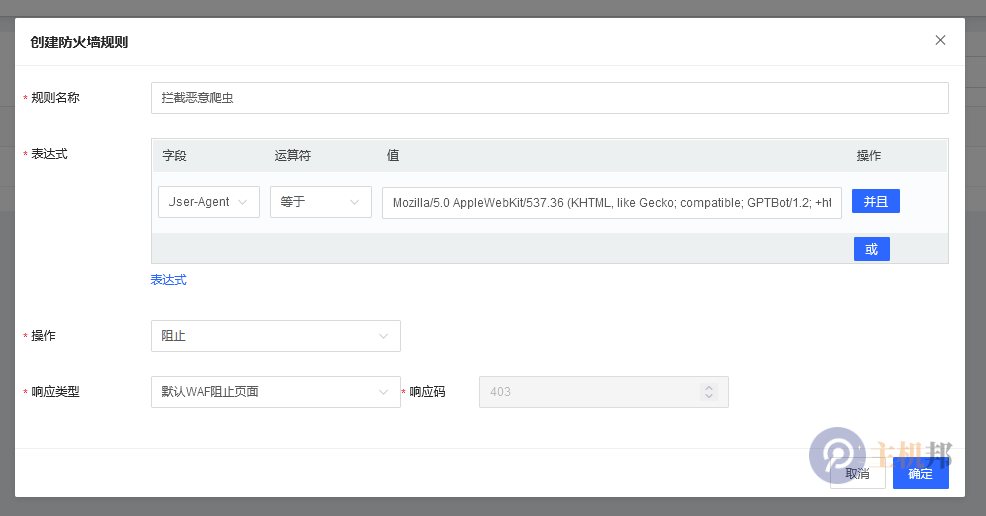
3.添加多个恶意爬虫拦截
点或按钮 再输入另一个恶意爬虫的User-Agent,比如DataForSeoBot的
如下图:
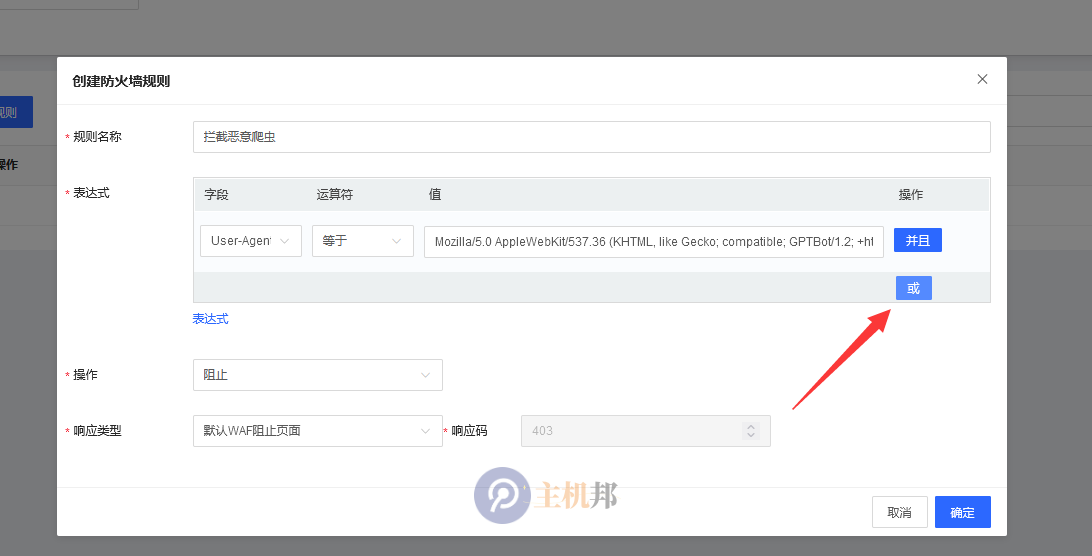
以此类推,把需要拦截的恶意爬虫全部加上,再点确定即可拦截。
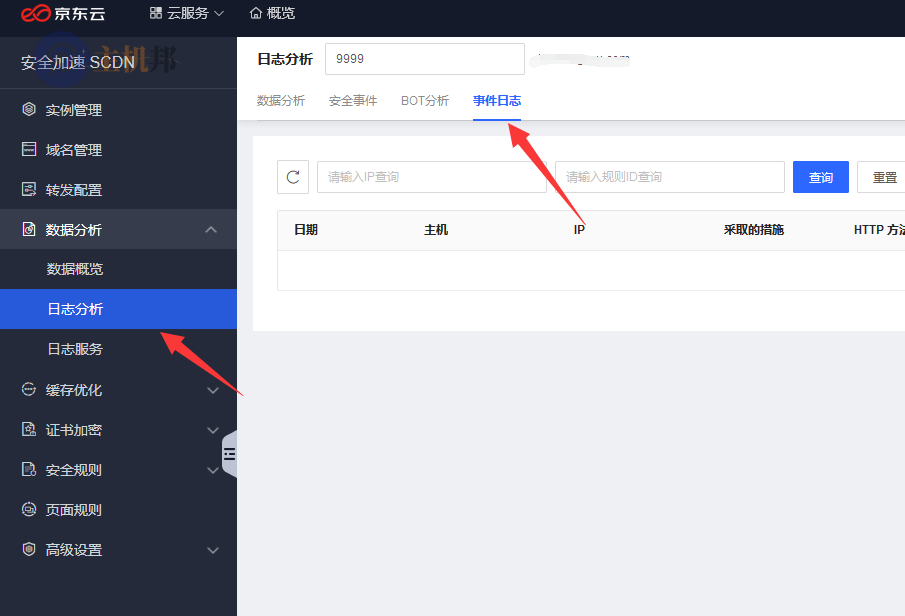
想知道是否正常拦截,可进入数据分析-事件日志查看。
下面主机邦根据客户反馈的恶意爬虫User-Agent分享给大家,需要拦截的直接把User-Agent加上就可以了。
1.GPTBot
GPTBot是OpenAI推出的一款网络爬虫机器人,抓取非常频繁,建议屏蔽。
User-Agent:
Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; GPTBot/1.2; +https://openai.com/gptbot)
2.AmazonBot
AmazonBot是亚马逊不同广告服务部门使用的爬虫,包括Amazon AdBot等,抓取频繁,对网站毫无用处,建议屏蔽。
User-Agent:
Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; Amazonbot/0.1; +https://developer.amazon.com/support/amazonbot) Chrome/119.0.6045.214 Safari/537.36
3.PanguBot
PanguBot 是由华为公司开发的一个爬虫,主要用于下载训练数据,以支持其多模态大型语言模型(LLM)PanGu 的训练。抓取非常疯狂,建议屏蔽。
User-Agent:Mozilla/5.0 (Linux; Android 7.0;) AppleWebKit/537.36 (KHTML, like Gecko) Mobile Safari/537.36 (compatible; PanguBot;pangubot@huawei.com)
4.SemrushBot
SemrushBot是Semrush发送的用于发现和收集新的和更新的Web数据的搜索机器人软件。抓取非常频繁,建议屏蔽。
User-Agent:
Mozilla/5.0 (compatible; SemrushBot/7~bl; +http://www.semrush.com/bot.html)
5.DataForSeoBot
DataForSeoBot是DataForSEO网站的蜘蛛,旨在向世界各地的SEO爱好者和专业人士提供高质量的数据。抓取非常频繁,建议屏蔽。
User-Agent:
Mozilla/5.0 (compatible; DataForSeoBot/1.0; +https://dataforseo.com/dataforseo-bot)
6.BLEXBot
BLEXBot是WebMeUp的蜘蛛爬虫,每天可以抓取上百亿个页面来收集反向链接数据,并将该数据提供给其链接索引(在SEO SpyGlass中使用的链接索引)。它是美国的一家外链反向链接查询工具网站所使用的爬虫。 抓取非常频繁,建议屏蔽。
User-Agent:
Mozilla/5.0 (compatible; BLEXBot/1.0; +http://webmeup-crawler.com/)