今日,GitHub 上一篇兼具技术深度与行业爆点的论文引发热议。该研究提出的 “LLM-Fingerprint 模型指纹技术”,直指通过注意力参数分布溯源预训练模型的可行性。核心结论显示:Pangu Pro MoE 模型与 Qwen-2.5 14B 模型的注意力参数分布相关性高达 0.927,这一数值远超行业内独立训练模型的正常差异范围,引发对模型知识产权的激烈讨论。
核心推断:从技术数据到版权质疑
论文作者通过实证分析提出两大关键推断:
- 技术路径非从零构建:Pangu Pro MoE 并非完全自研,而是通过 “upcycling(持续训练 + 架构调整)” 基于 Qwen 模型进行改造,即使从 Dense 架构转为 MoE 架构,核心参数指纹仍保留显著继承特征。
- 自研声明存疑:技术文档中 “完全自研” 的表述与参数指纹分析结果矛盾,可能涉及版权侵权与技术报告真实性争议。
模型指纹技术:如何锁定 “参数血缘”?
该技术的核心逻辑可拆解为三步:
- 特征提取:抓取模型各层多头注意力机制中 Q、K、V、O 矩阵的标准差,按层序排列并归一化,形成唯一的 “参数指纹序列”。
- 相关性计算:通过皮尔逊相关系数衡量不同模型的指纹序列相似度。实验证明,即使经历架构改造(如 MoE 拆分)或大规模微调,该指纹仍保持稳定性。
- 继承性验证:在已知继承关系的模型(如 Llama 变体、Qwen 社区微调版)中,指纹相关性显著高于独立训练模型(即使同属 Qwen 家族内部不同型号)。
争议升级:1 小时速答与学术交锋
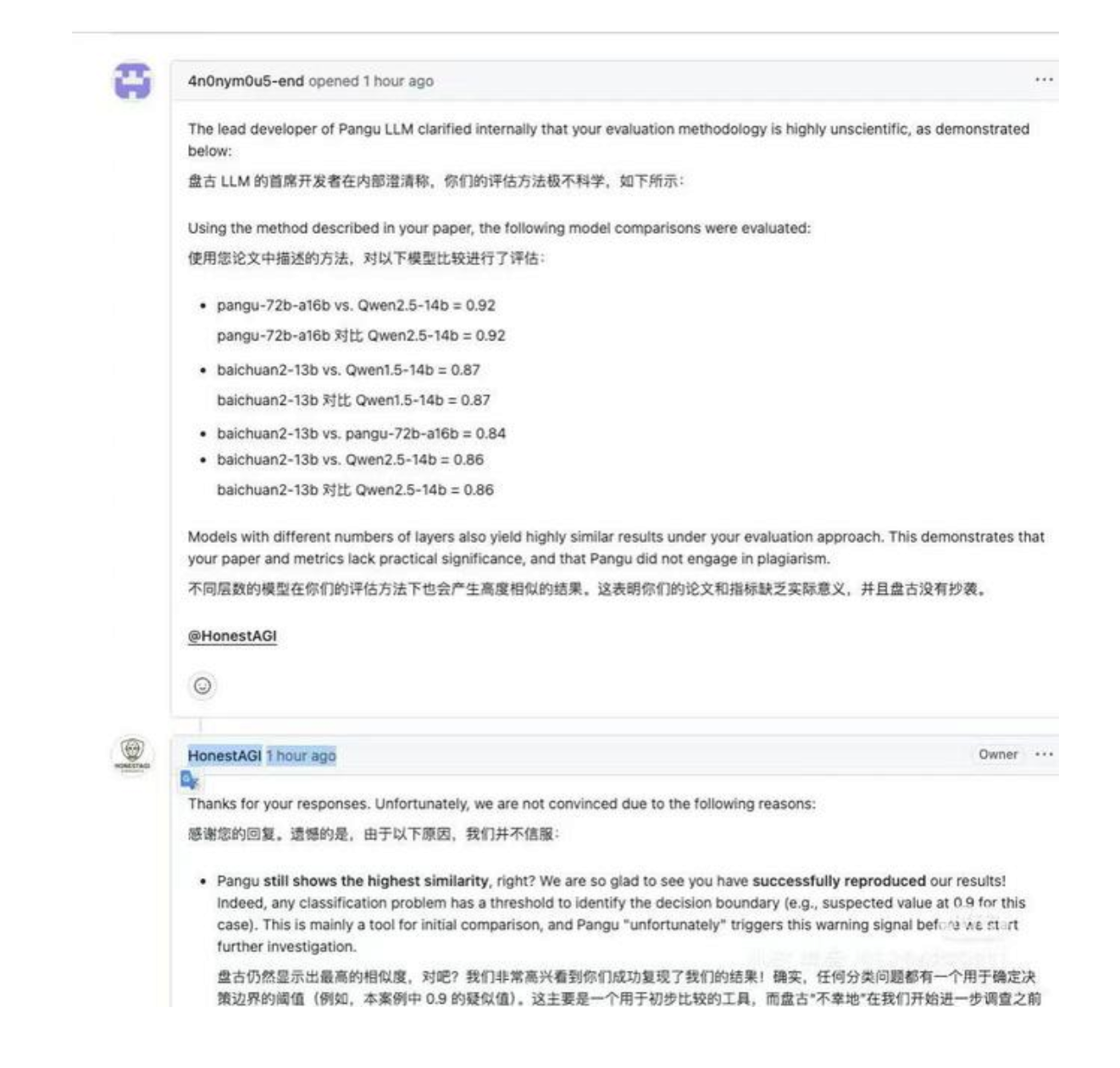
论文发布 1 小时后,涉事团队在 GitHub Issue 中紧急回应,全盘否认抄袭指控,并称 LLM-Fingerprint 的评估方法 “缺乏科学依据”。但论文作者 HostAGI 团队随即在 Issue#8 中反驳,指出参数分布的高相关性已超越 “巧合” 范畴,双方围绕技术方法论展开激烈辩论。
吃瓜群众视角
当前事件已从技术讨论升级为行业伦理争议。脉脉等平台爆料显示,事件背后或牵扯 AI 实验室的人事博弈。正如网友调侃:”到底是自研还是换皮,就看 Pangu 能否拿出推翻 0.927 相关性的硬证据。” 目前,技术圈正等待涉事方进一步举证,让子弹再飞一会儿。