很多站长发现:明明已经封了UA、限了频率,爬虫还是源源不断。因为现在的爬虫越来越“聪明”——UA可以伪装成Chrome,频率可以模仿人类,甚至连IP都用上了秒拨池。但有一个东西,爬虫往往容易露馅:自定义请求头。
今天我们就来聊聊,如何利用百度云防护的自定义规则,通过分析请求头中的蛛丝马迹,精准识别并拦截那些“伪装成正常用户”的爬虫。
一、 为什么自定义请求头能识别爬虫?
正常的浏览器请求,会携带一套完整的HTTP头,包括:
Accept:声明客户端能接收的内容类型Accept-Language:用户的语言偏好Accept-Encoding:支持的压缩方式User-Agent:浏览器标识Referer:来源页面Sec-Ch-Ua、Sec-Ch-Ua-Mobile、Sec-Ch-Ua-Platform:现代浏览器的安全特性头Cookie:会话信息
而很多爬虫(尤其是低级爬虫)为了简化代码,会遗漏某些头,或者头的值异常。比如:
- 缺少
Accept-Language(正常浏览器一定会带) - 缺少
Sec-Ch-Ua系列头(现代浏览器必备) Accept值非常简略(比如只有*/*)Referer和请求URL不匹配- 多个头之间逻辑矛盾(如声称是Chrome却没有
Sec-Ch-Ua)
二、 百度云防护支持哪些请求头匹配?
百度云防护的自定义规则中,Header是一个非常重要的匹配字段。你可以选择任何一个HTTP头,判断它是否存在、不存在、等于、包含某个值。
支持的常见头包括:
User-AgentRefererAcceptAccept-LanguageAccept-EncodingCookieHostOriginX-Forwarded-For- 以及任何自定义头(如
X-Requested-With、X-Custom-Token)
三、 实战规则示例:识别并拦截爬虫
下面给出几条基于自定义请求头的典型拦截规则,可以直接在百度云防护中配置。
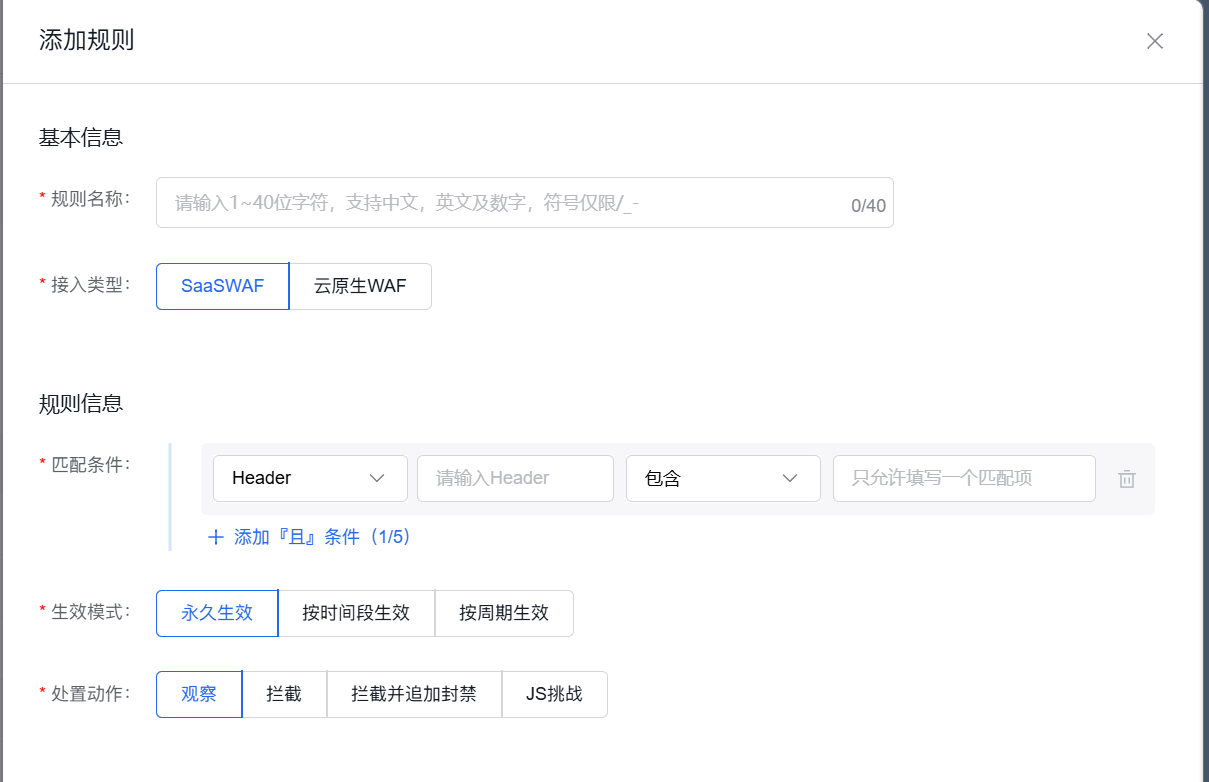
规则1:拦截缺少Accept-Language的请求
正常浏览器请求一定会携带Accept-Language,告诉服务器用户的语言偏好。如果缺失,极大概率是爬虫。
配置:
- 匹配条件1:
Accept-Language→ 不存在 - 处置动作:拦截
注意:如果网站有API被其他服务调用,可能也会缺少这个头,建议先用“观察”模式测试。
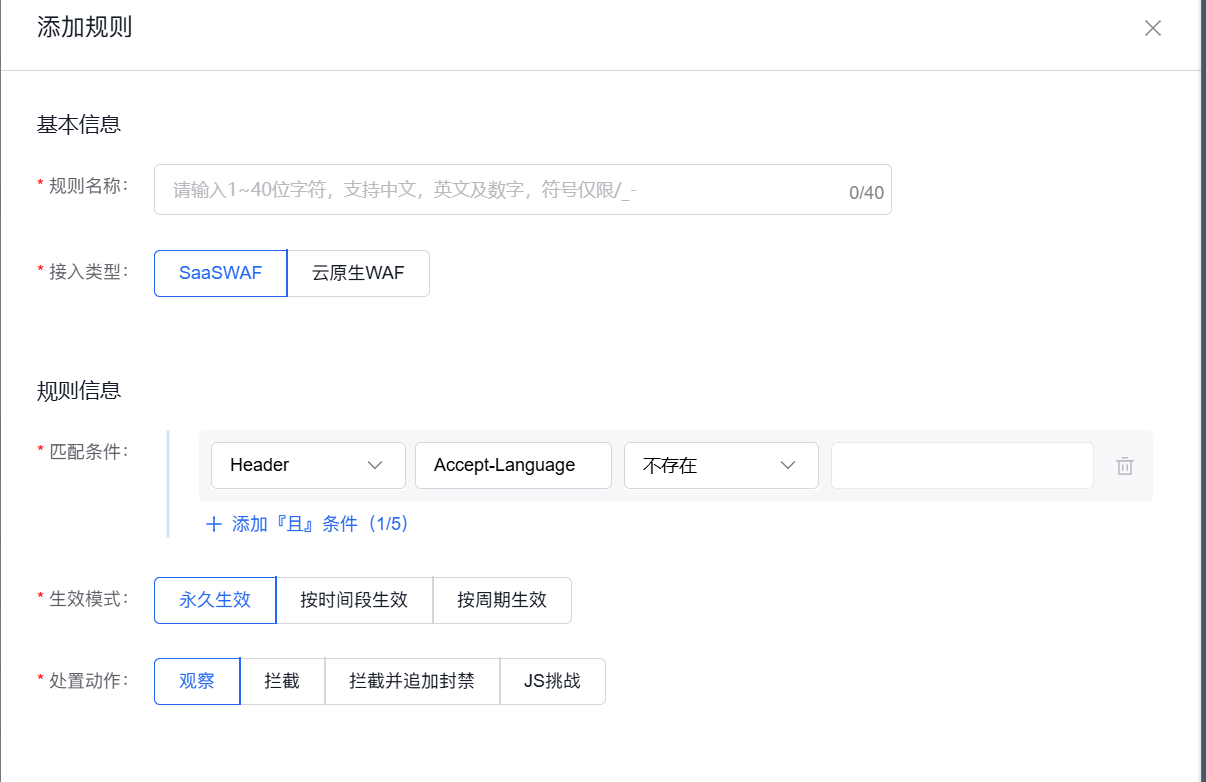
规则2:拦截缺少现代浏览器安全头的请求
Chrome、Edge等现代浏览器会自动携带Sec-Ch-Ua、Sec-Ch-Ua-Mobile、Sec-Ch-Ua-Platform等头。如果UA声称是Chrome,却没有这些头,那就是伪造。
配置(组合条件“且”):
- 条件1:
User-Agent→ 包含 →Chrome - 条件2:
Sec-Ch-Ua→ 不存在 - 处置动作:拦截
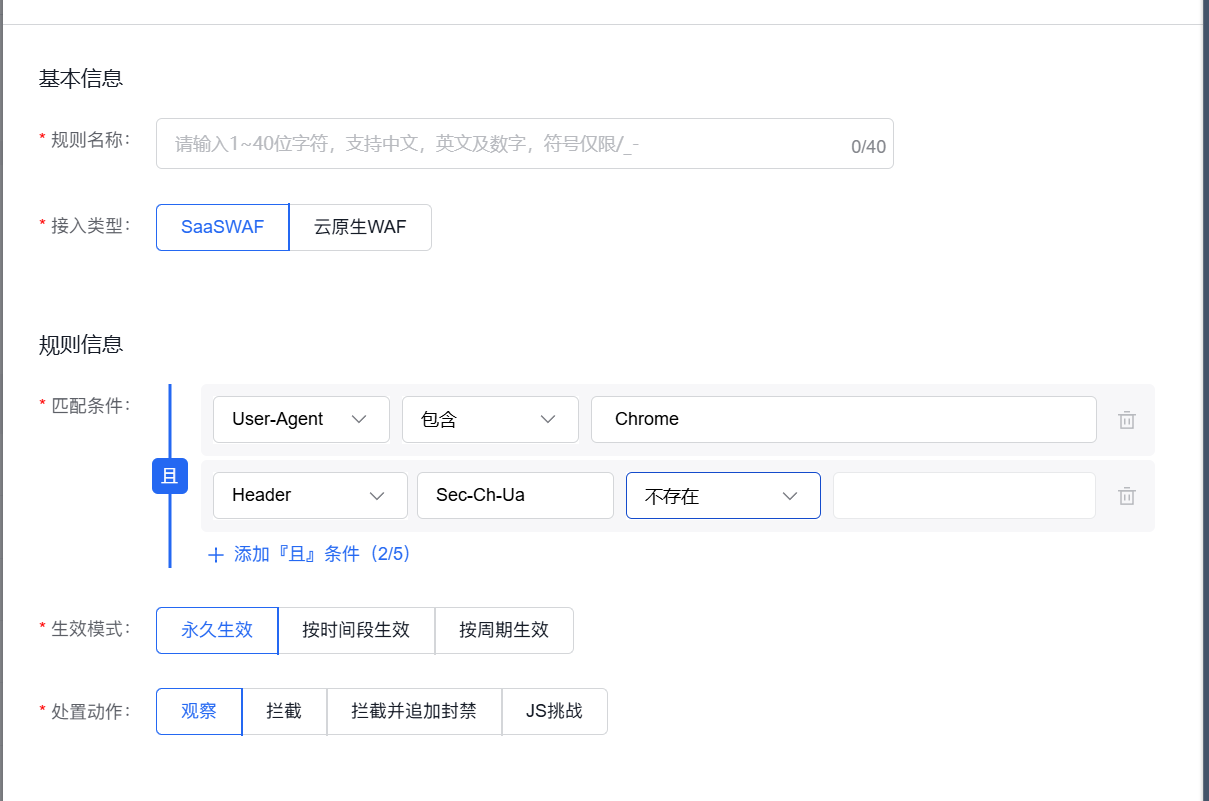
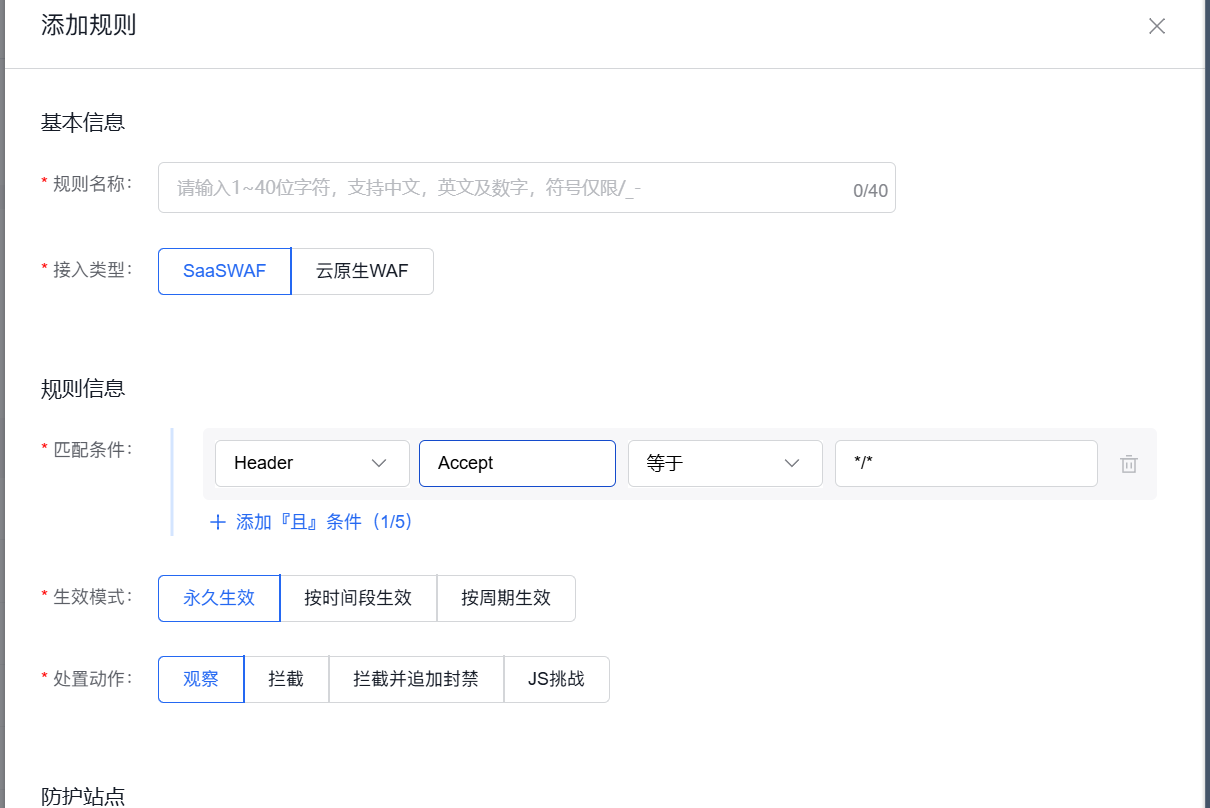
规则3:拦截Accept值异常的请求
正常浏览器请求HTML页面时,Accept通常包含text/html;请求CSS时包含text/css;请求JS时包含application/javascript。如果Accept只有*/*或*,往往是扫描器或低级爬虫。
配置:
- 匹配条件:
Accept→ 等于 →*/* - 处置动作:拦截
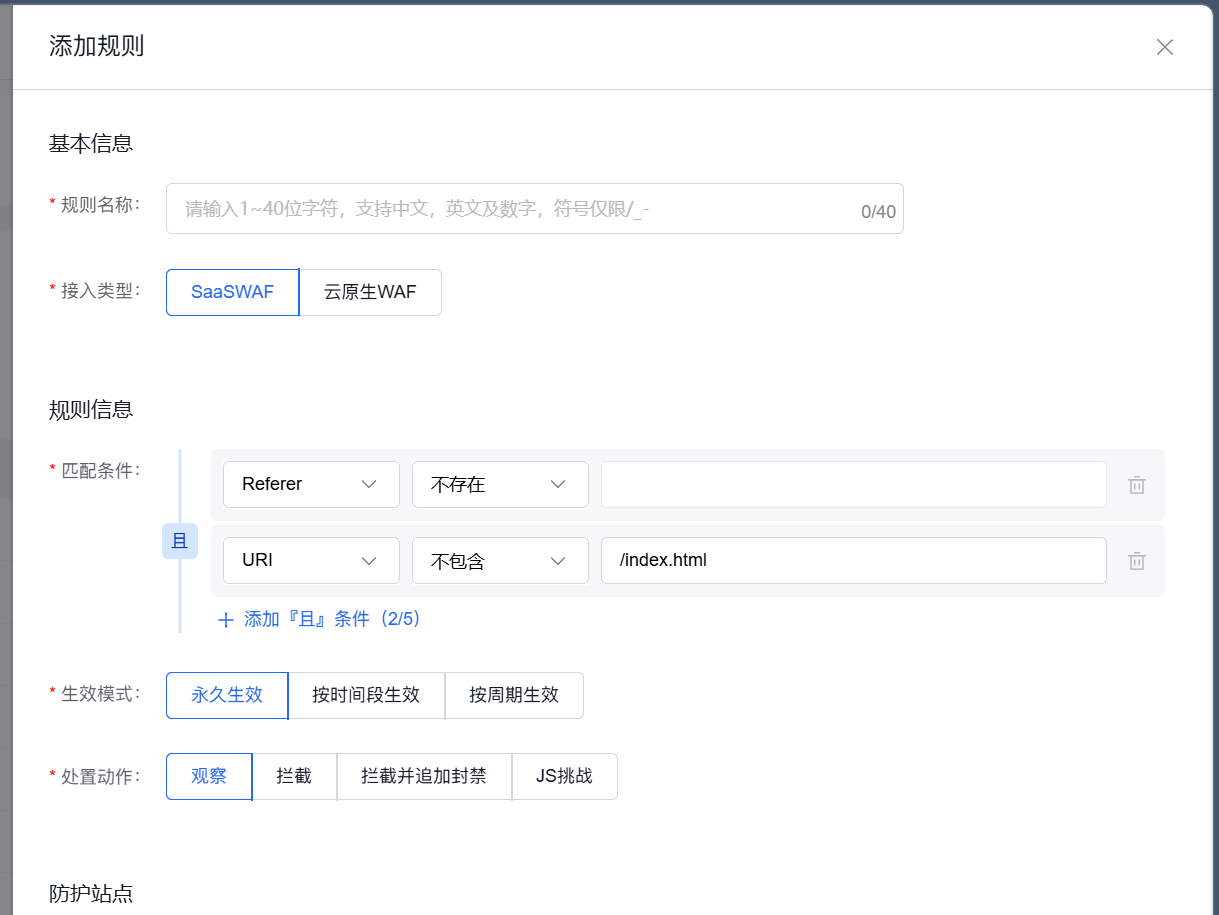
规则4:拦截Referer和请求路径不匹配
如果请求的是内页资源,但Referer是空或者是根域名,也可能是爬虫在直接请求资源。
配置(组合条件“且”):
- 条件1:
Referer→ 不存在 或 等于 →https://你的域名/ - 条件2:
URI→ 不包含 →/index.html或/(排除首页) - 处置动作:拦截
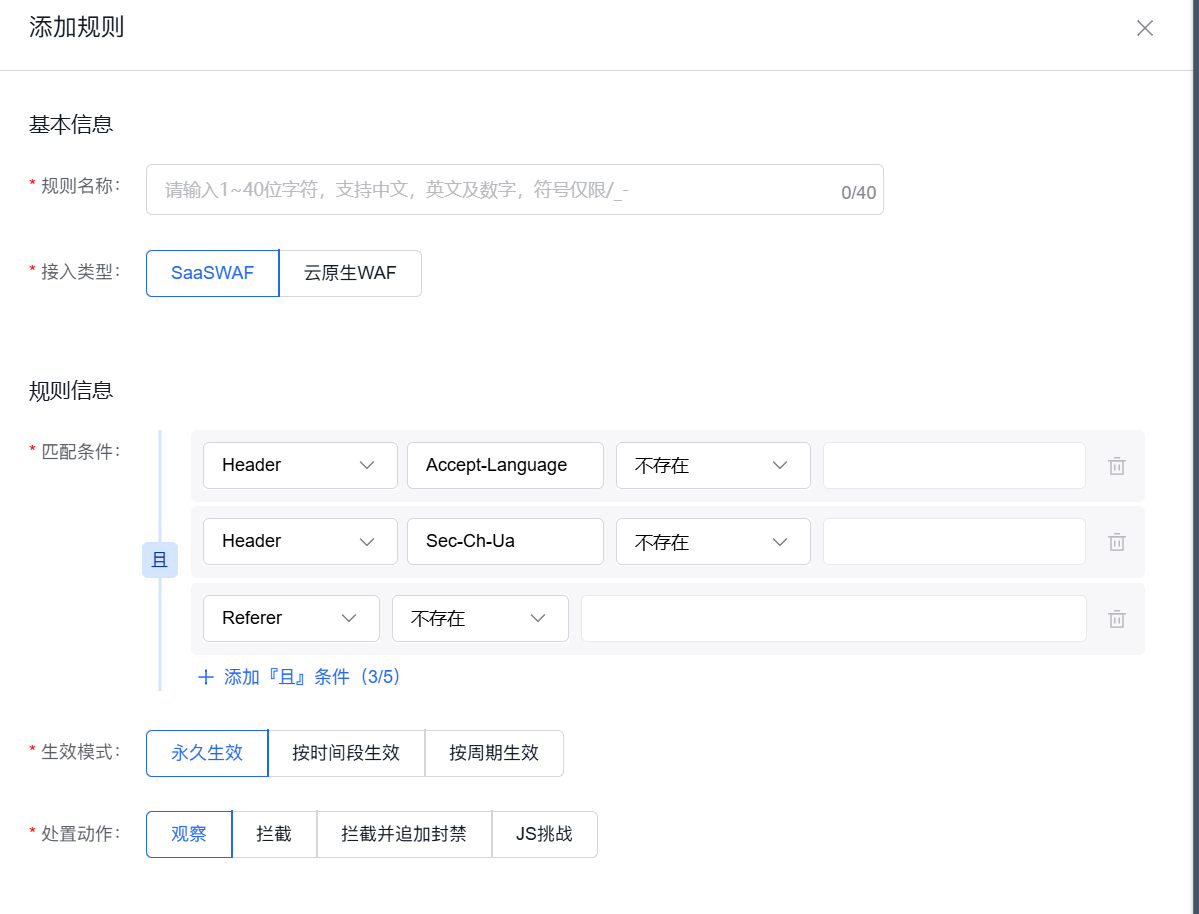
规则5:拦截特定头缺失的组合(更精准)
单个头缺失容易误杀,但多个头同时缺失,基本可以确定是爬虫。
配置(组合条件“且”):
- 条件1:
Accept-Language→ 不存在 - 条件2:
Sec-Ch-Ua→ 不存在 - 条件3:
Referer→ 不存在 或 等于 → 空 - 处置动作:拦截
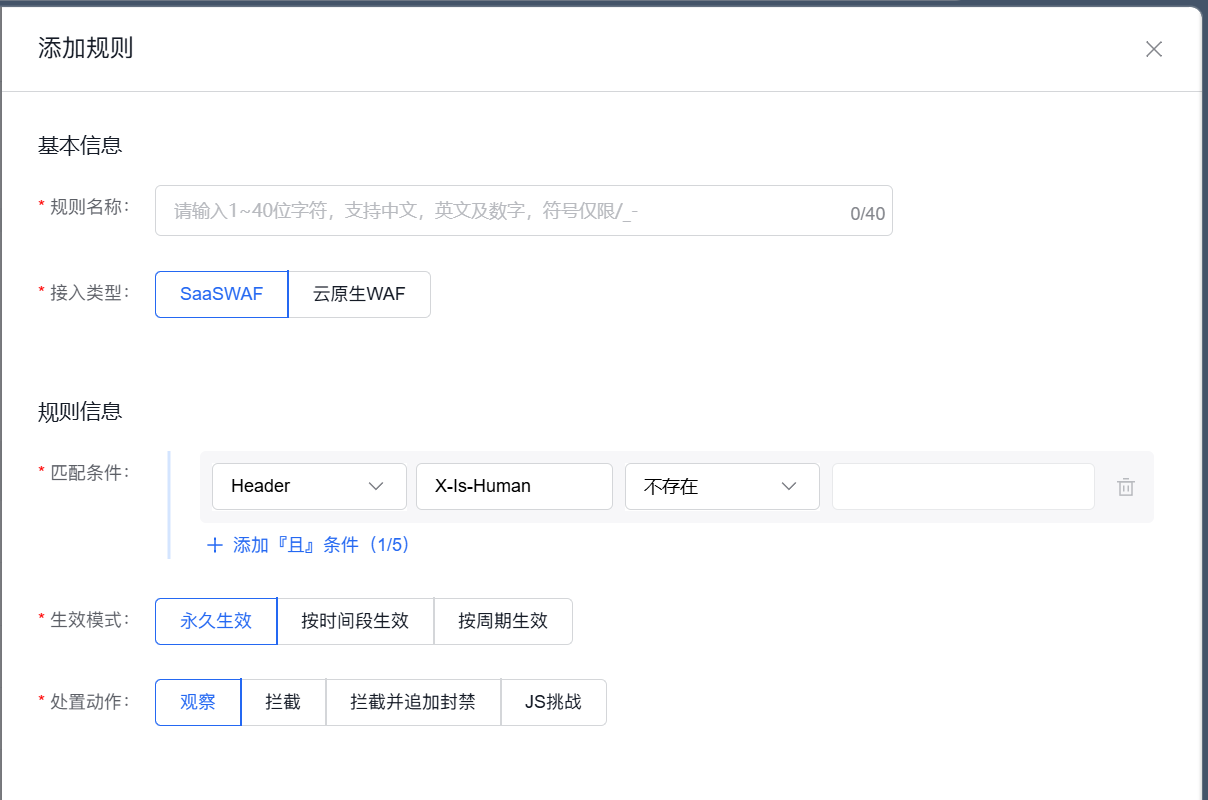
四、 更进阶的玩法:通过自定义头“钓鱼”
如果你有技术能力,可以在前端代码中主动添加一个自定义请求头(如X-Custom-Token),值为一段加密字符串。正常用户通过浏览器访问时,会携带这个头;爬虫直接抓取HTML,不会执行JS,自然不会带上。
步骤:
- 在网站前端JS中,给所有
fetch或XMLHttpRequest请求添加一个自定义头,如X-Is-Human: true。 - 在百度云防护中配置规则:
- 匹配条件:
X-Is-Human→ 不存在 - 处置动作:拦截
- 匹配条件:
效果:所有不经过正常页面渲染的请求(如直接请求API、静态资源)都会被拦截,而正常用户访问时,因为浏览器执行了JS,请求头自动带上,畅通无阻。
注意:这种方式只适用于AJAX/API请求,不适用于HTML页面的首次加载。
五、 组合策略:让爬虫无处遁形
单一规则总有被绕过的可能,但多条规则叠加后,爬虫就难了。推荐以下组合:
- 基础规则:拦截缺少
Accept-Language或Sec-Ch-Ua的请求。 - 路径规则:对敏感URL(如
/api/)启用自定义头验证(X-Custom-Token)。 - 频率规则:配合CC防护,限制单一IP对特定路径的访问频率。
- 情报规则:结合IP动态情报,封杀代理IP、云服务IP。
- JA4规则:锁定攻击工具指纹,让换IP、换UA的爬虫也无所遁形。
配置时,建议先设为“观察”模式,观察几天日志,确认误杀率后再改为“拦截”。
六、 主机吧小结:用好自定义请求头,让爬虫“原形毕露”
爬虫可以伪装UA、可以换IP,但很难完全模仿真实浏览器的请求头组合。百度云防护的自定义规则,让你可以灵活利用这些细微差异,精准识别并拦截恶意爬虫。
如果你还在为爬虫发愁,不妨试试上面的方法。当然,如果你觉得配置规则太麻烦,或者想获得更专业的防护建议,欢迎联系主机吧。我们提供免费安全评估和配置指导,帮你用最简单的方法,挡住最狡猾的爬虫。
主机吧 | 百度云防护官方合作伙伴
提供WAF接入、高防CDN、高防IP、高防服务器、SSL证书一站式服务
让爬虫原形毕露,让网站干干净净。